

Абстрактный
Обнаружение людей остается популярной и сложной задачей компьютерного зрения. В этой статье мы анализируем основанные на частях модели для обнаружения людей, чтобы определить, какие компоненты их конвейера могут принести наибольшую пользу при улучшении. Мы выполняем эту задачу, изучая многочисленные детекторы, сформированные из комбинаций компонентов, выполняемых людьми и машинами. Модель, основанную на частях, которую мы изучаем, можно грубо разбить на четыре компонента: обнаружение признаков, обнаружение частей, оценка пространственных частей и контекстное рассуждение, включая немаксимальное подавление. Наши эксперименты показывают, что обнаружение частей является самым слабым звеном для сложных наборов данных обнаружения людей. Немаксимальное подавление и контекст также могут значительно повысить производительность. Однако,
Мотивация
Обнаружение человека — важная, но открытая и сложная проблема компьютерного зрения. В последнее время детекторы людей добились значительного прогресса, используя модели на основе частей. Исследователи исследовали различные характерные представления изображений, различные модели внешнего вида для частей, сложное пространственное моделирование конфигураций объектов, а также выразительные немаксимальные модели подавления и контекста. Каждый из этих подходов предлагает сложный набор взаимозависимых компонентов для получения окончательных результатов обнаружения. Хотя дополнительная сложность подходов привела к повышению производительности, понимание роли каждого компонента в окончательной точности обнаружения затруднено.
Предложение

Эксперименты и результаты
Мы оцениваем точность обнаружения различных детекторов (см. ниже), состоящих из различных комбинаций компонентов, выполняемых людьми или машинными реализациями.

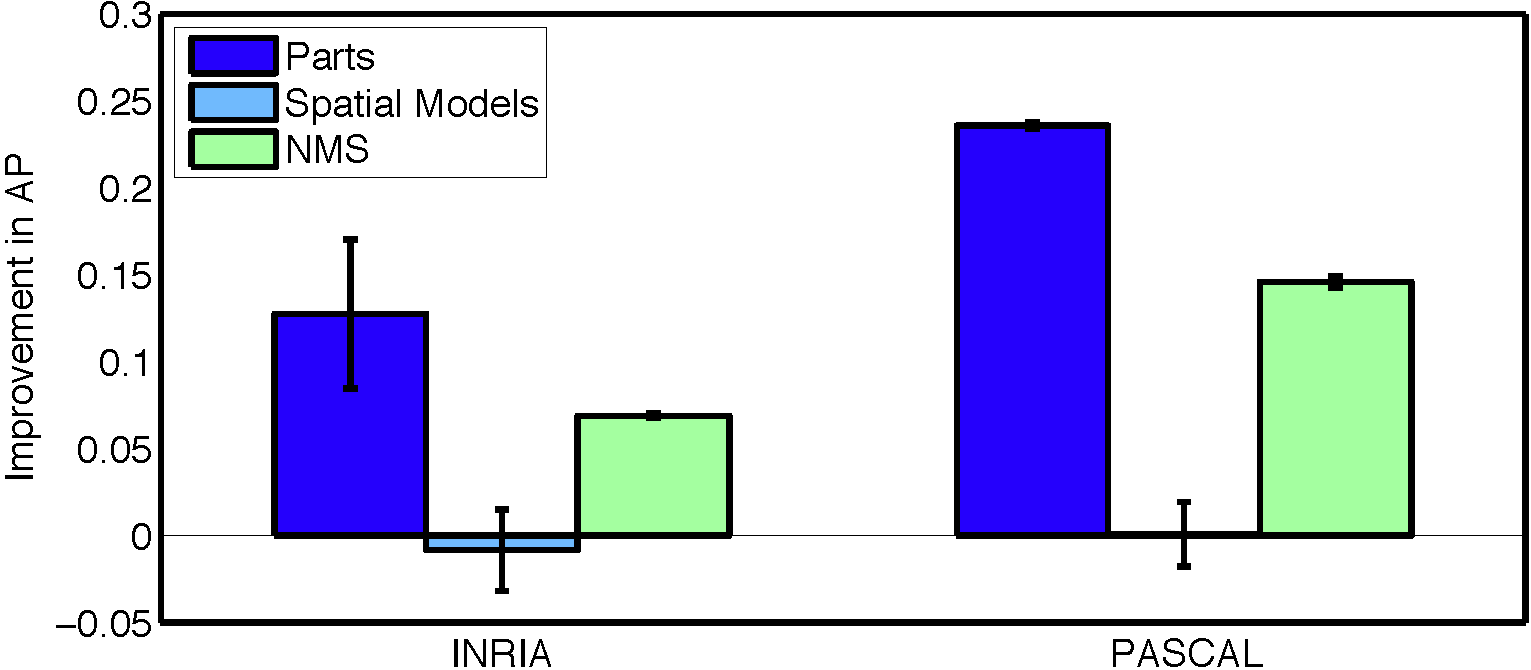
Сравнения между различными подмножествами этих детекторов позволяют нам разделить влияние каждого из компонентов в конвейере обнаружения людей на основе частей. Хотя мы рекомендуем вам ознакомиться с подробными сравнениями в статье, сводку результатов, полученных на наборах данных PASCAL 2007 и INRIA , можно увидеть ниже. Мы обнаружили, что обнаружение частей является самым слабым звеном в обнаружении людей на основе частей. Немаксимальное подавление также нетривиальным образом влияет на производительность. Однако использование пространственных моделей человека или машины существенно не влияет на точность обнаружения.
Среди большого количества человеческих данных, которые мы собрали в рамках наших экспериментов, мы считаем, что следующее может представлять интерес для сообщества.
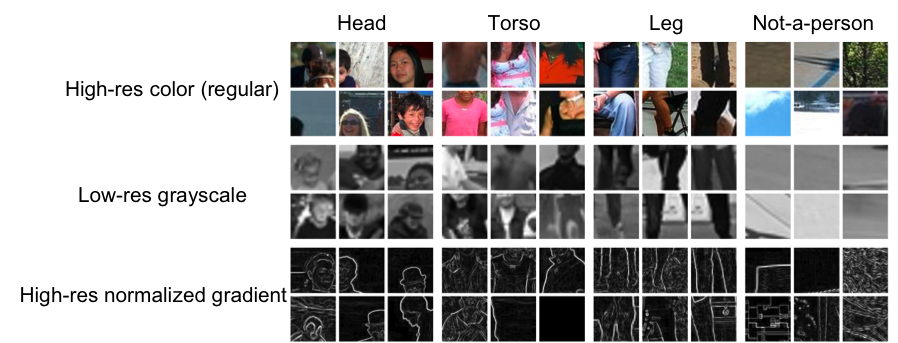
У нас были цвет (обычный), оттенки серого и нормализованный градиент. В итоге получилось 45 316 x 6 = 271 896 патчей. 10 человек отнесли каждый патч к одной из 8 категорий на сайте Amazon Mechanical Turk.
Ниже можно увидеть снимок данных, на котором показаны примеры участков, классифицированных большинством испытуемых как голова, туловище, нога и ни одного.
Точно так же у нас также было 10 человек, которые классифицировали перекрывающиеся подокна изображения (всего 6 218 x 6 = 37 308 окон) как содержащие человека или нет (аналогично обнаружению «корня»). Как и в случае с частями, подокна были извлечены из цветных изображений с высоким и низким разрешением, изображений в градациях серого и нормализованных градиентных изображений.
Мы предоставляем эту часть (патч) и корневую (окно) классификационные данные в виде набора данных Part Patch.
** Загрузить ** Набор данных исправления части [89,3 МБ]
Визуализации
Часть наших исследований на людях требовала, чтобы люди обнаруживали людей, используя предварительно вычисленный набор частей. Части могут быть обнаружены другими людьми или машиной. Чтобы гарантировать, что никакая предварительная информация, кроме обнаруженных частей, не используется людьми, мы создали визуализацию, которая отображает обнаружение частей, но не другую информацию на изображении. Пример визуализации можно увидеть ниже.
